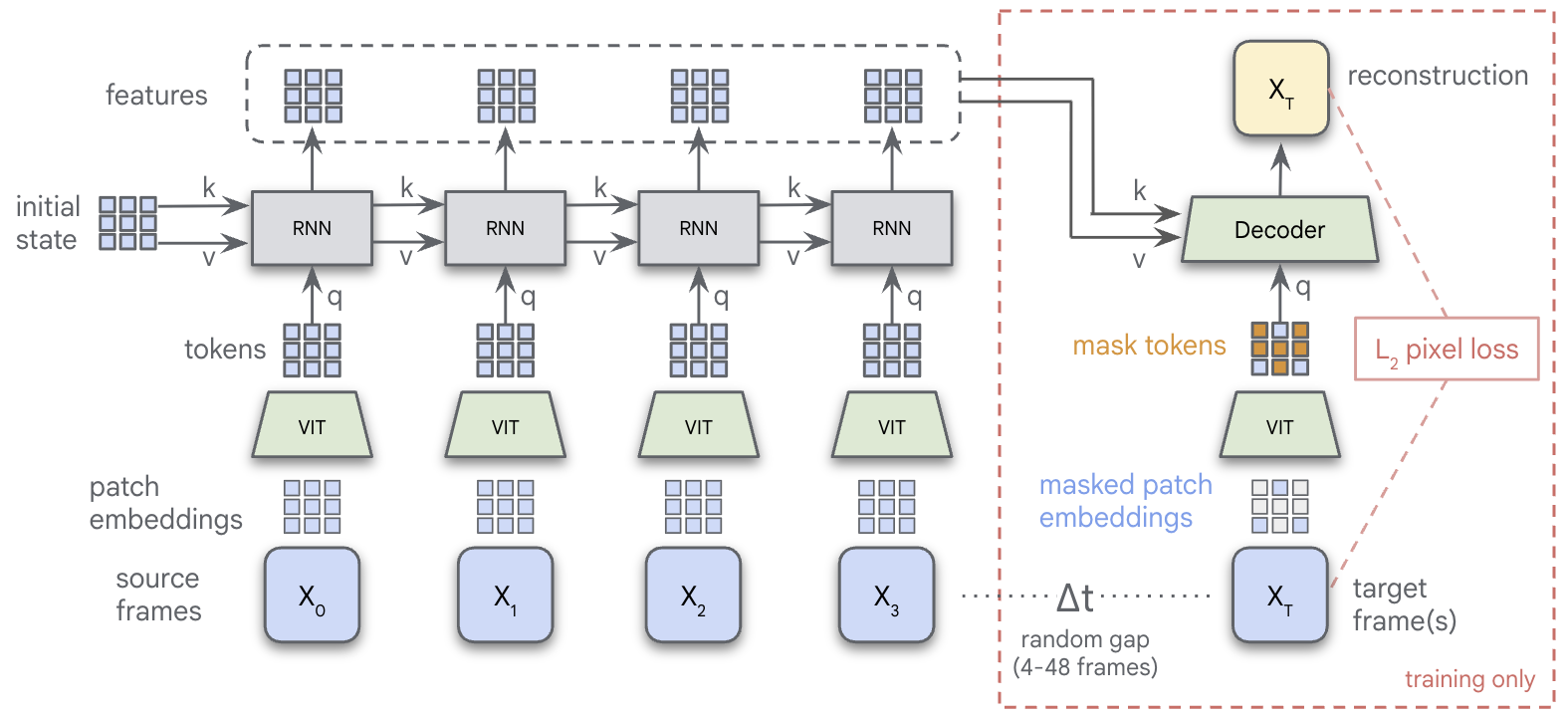
We present Recurrent Video Masked-Autoencoders
(RVM): a novel approach to video representation learning
that leverages recurrent computation to model the tempo-
ral structure of video data. RVM couples an asymmetric
masking objective with a transformer-based recurrent neu-
ral network to aggregate information over time, training
solely on a simple pixel reconstruction loss. This design
yields a highly efficient "generalist" encoder: RVM achieves
competitive performance with state-of-the-art video models
(e.g. VideoMAE, V-JEPA) on video-level tasks like action
classification, and point and object tracking, while matching
or exceeding the performance of image models (e.g. DI-
NOv2) on tasks that require strong geometric and dense
spatial features. Notably, RVM achieves strong performance
in the small-model regime without requiring knowledge dis-
tillation, exhibiting up to 30× greater parameter efficiency
than competing video masked autoencoders. Finally, we
demonstrate that RVM’s recurrent nature allows for stable
feature propagation over long temporal horizons with lin-
ear computational cost, overcoming some of the limitations
of standard spatio-temporal attention-based video models.
Ablation studies further highlight the factors driving the
model’s success, with qualitative results showing that RVM
learns rich representations of scene semantics, structure,
and motion.